This is the OCR tab of PDF2XL OCR's options dialog. Click on any option for an explanation on what it does.
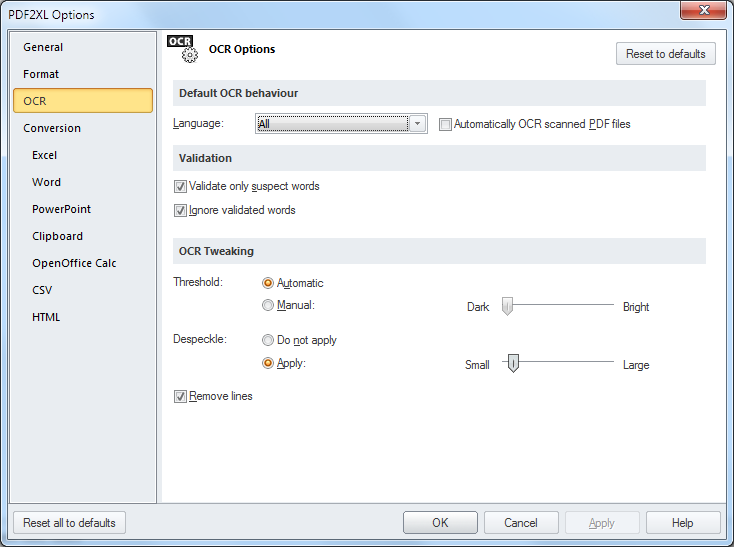
Allows the user to select the language of the dictionary used in the OCR process. Words that do not appear in the dictionary will have a higher chance of being marked as suspect.
If 'all' is selected (which is the default), the OCR process will guess the language of the word.
If this option is checked, PDF2XL OCR will automatically perform OCR when a new scanned PDF document is opened.
If this is left unchecked, OCR Validation will try to validate all words in the document, rather than only ones marked as suspect.
Ignore validated wordsIf this is checked, opening the OCR Validation dialog will skip words that were already validated. If unchecked, the dialog will ask to validate all words
You can either allow PDF2XL OCR to select an automatic monochrome threshold, or set it manually. Change this setting if the scanned page is either very light or very dark.
Despeckle
By setting this option you can make the OCR process ignore small dots and imperfections in the scanned image. If the scanned document has a lot of 'noise', this option can help enormously.
To use it, check the despeckle box, and select the maximum size of the dot to remove. Moving the bar to the right will make PDF2XL OCR remove larger and larger 'dots', up to removing quite sizable chucks.
If this option is set, PDF2XL OCR will try to remove vertical and horizontal lines before processing the image. This is mostly useful when trying to process an image scanned from old computer print-out papers that have pre-printed lines on them.